Systematiska översikter - för forskare
Ska du göra en systematisk översikt? Vi på biblioteket får ofta frågor om vad som egentligen kännetecknar en systematisk översikt, vad som skiljer den från andra typer av översikter, och hur man bäst gör för att söka systematiskt. På den här sidan går vi igenom vad som kan vara bra att tänka på i arbetet med att utforma systematisk en sökstrategi.

Pilotavsnittet av KIB-podden
Lyssna till pilotavsnittet av KIB-podden där Wim Grooten, docent, forskare och lektor, är gäst och systematiska översikter diskuteras!
Vad är en systematisk översikt?
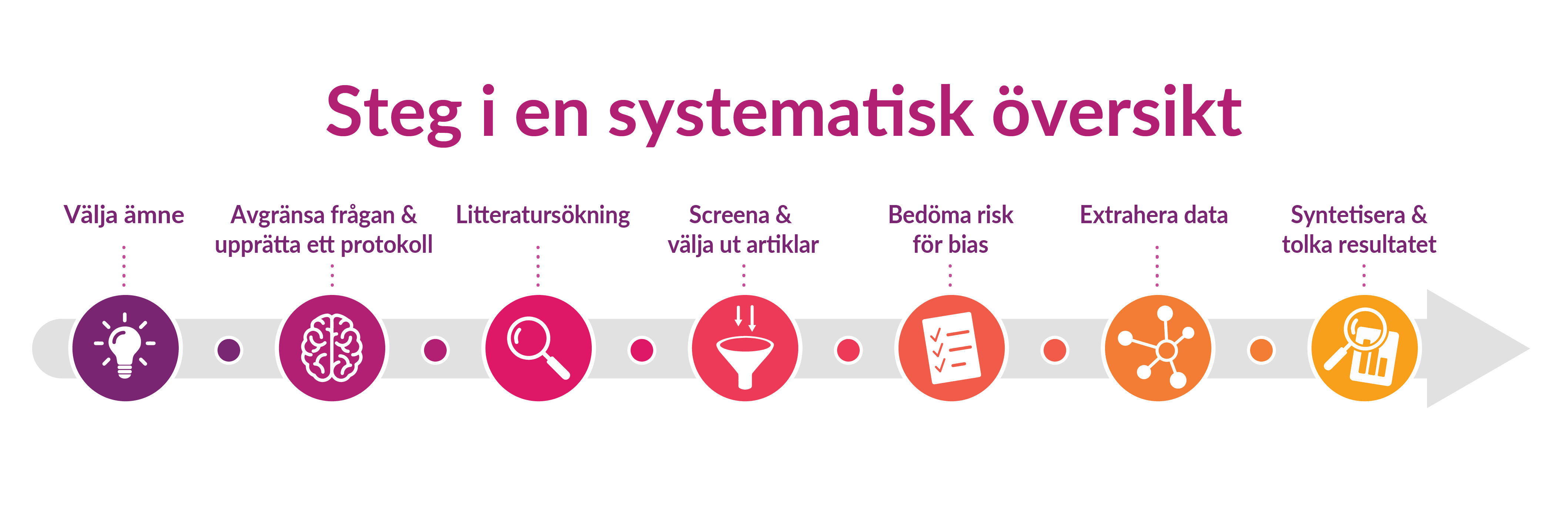
En systematisk översikt är en litteraturöversikt som enligt en specifik metodologi sammanställer all tillgänglig forskning inom ett avgränsat ämnesområde. Systematiska översikter placeras vanligen högst upp i evidenshierarkier eftersom de analyserar och värderar resultatet från samtliga originalstudier inom ett ämne.
Vid arbetet med en systematisk översikt ska en noggrann metodologi följas under hela processen – från formulerandet av forskningsfrågan, protokoll och litteratursökning till sammanställning, granskning och analys. Alla steg ska också dokumenteras. Systematiska översikter innehåller ibland så kallade metaanalyser, där den data som samlats in sammanställs och genomgår en statistisk analys.
Det finns flera metod- och läroböcker som beskriver processen och de olika steg som vanligtvis ingår i arbetet med en systematisk översikt. Det finns även internationella riktlinjer för hur systematiska översikter ska rapporteras, PRISMA Guidelines.
Tips på metodlitteratur:
- SBU:s metodbok
- Cochrane Handbook for Systematic Reviews of Interventions - Cochrane Collaboration
- JBI Manual for Evidence Synthesis - JBI, University of Adelaide
Att tänka på innan du börjar
Vilken typ av översikt ska du göra? Det finns flera olika slags översikter, och vilken som passar bäst beror till exempel på hur lång tid du har, och vilken typ av forskningsfråga du utgår från. Cornell University Library har gjort ett beslutsträd där du kan du se vilken slags översikt som kan vara lämplig för dig.
Hur mycket tid har du till förfogande för projektet? Det tar vanligtvis mellan 6 månader och 2 år att genomföra en systematisk översikt. Har du mindre tid till förfogande kan det passa bättre att göra en rapid review.
Har du alla kompetenser som behövs i ditt team? Förutom kunskaper kring ämnet och forskningsmetodik kan det behövas expertis inom statistisk analys och litteratursökning. För att minska risken för bias rekommenderas att det är minst två personer som, oberoende av varandra, går igenom alla träffar och och väljer vilka studier som ska inkluderas i översikten.
Har du tillgång till de verktyg som behövs i projektet? Förutom lämpliga databaser att söka i är det bra att ha ett program för hantering av referenser, till exempel EndNote. Det kan även vara bra att använda något program för screeningen av referenser, som exempelvis Rayyan eller Covidence.
Finns det en liknande översikt på gång redan? Gör gärna en sökning i till exempel PROSPERO för att se så att inget liknande projekt är på gång.
Protokoll - Planera för att skriva ett protokoll. Protokollet kan registreras i till exempel PROSPERO, eller i något öppet repositorium som till exempel Open Science Framework eller Figshare
Skapa en tydlig forskningsfråga
En central utgångspunkt för en systematisk sökning är en väl avgränsad och tydlig forskningsfråga. Det finns flera olika ramverk som kan användas för att strukturera och avgränsa forskningsfrågan. Biblioteket på University of Plymouth har en bra sida där du kan läsa mer om de mest använda ramverken. Vid kliniska frågeställningar är det vanligt att använda PICO-strukturen: Population, Intervention, Control och Outcome.
Skapa sökblock
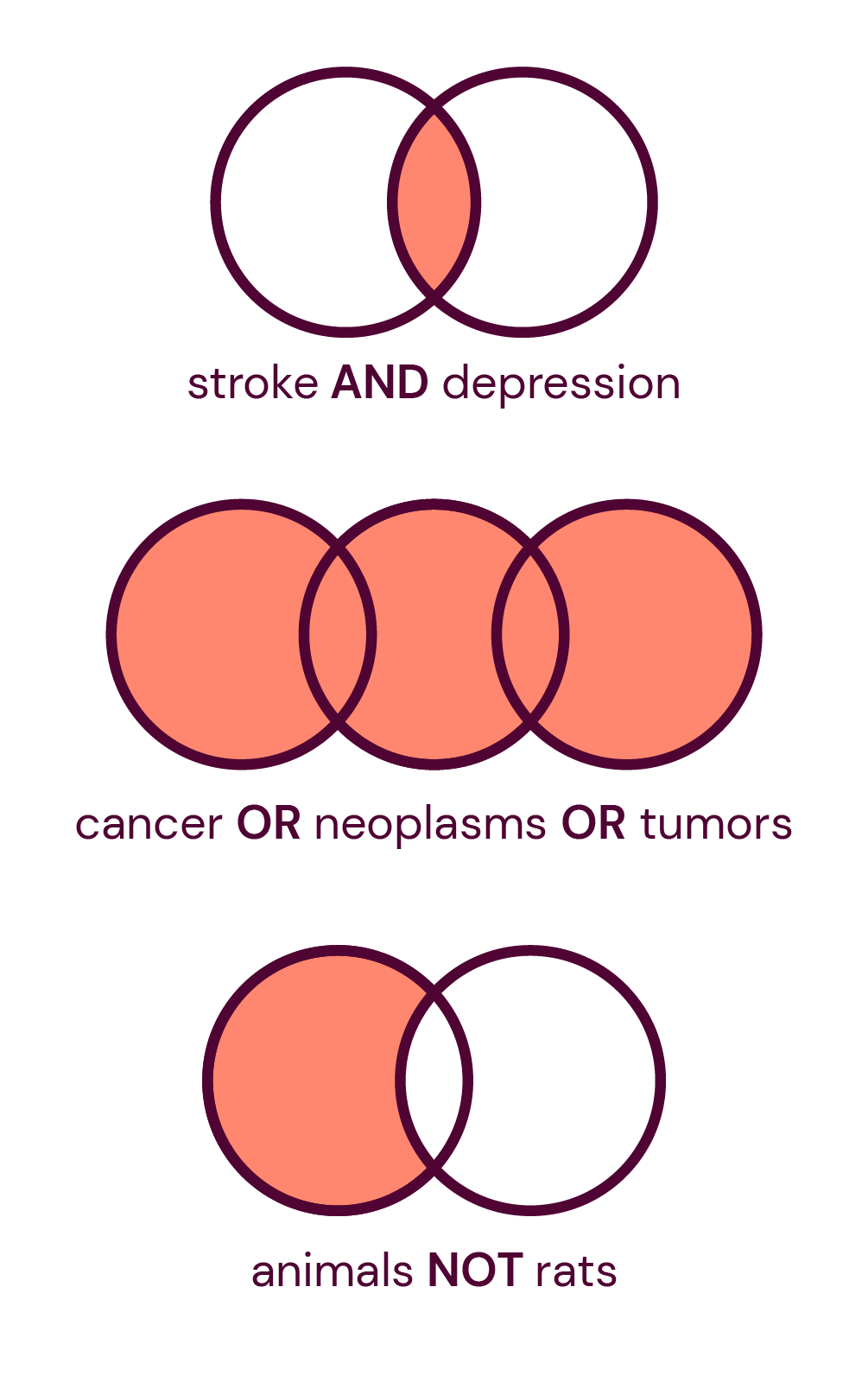
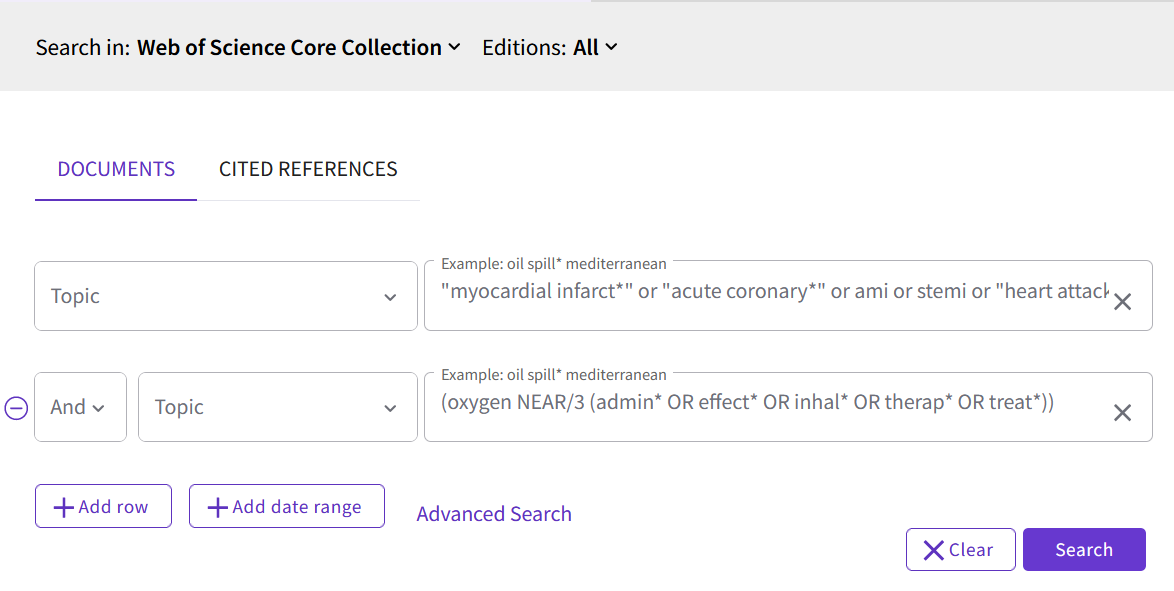
För att forskningsfrågan ska bli "sökbar" behöver du först identifiera frågans huvudbegrepp. Utifrån huvudbegreppen skapas sökblock som blir grunden för de söksträngar som används i de olika databaserna. Vi kan ta ett exempel med följande frågeställning:
- Does routine use of inhaled oxygen in acute myocardial infarction improve patient-centred outcomes, in particular pain and death?
I exemplet har vi markerat några av de potentiella huvudbegreppen i frågeställningen, som skulle kunna utgöra sökblock. Det är dock sällan som samtliga fyra delar av PICO-frågan används i själva sökningen, ofta läggs fokus på population och intervention. I ovanstående exempel alltså P = patienter med hjärtinfarkt och I = syrgasbehandling.
En generell princip är att en sökning till en systematisk översikt bör innehålla få sökblock. Ju fler sökblock du har, desto smalare blir sökningen. Därmed finns också en större risk att missa relevanta artiklar.
Utveckla en sökstrategi
En central del av en systematisk översikt är en uttömmande litteratursökning. Sökningen ska ha hög sensitivitet, dvs. den ska vara utformad för att hitta alla, eller så många som möjligt, av de relevanta studierna inom ett ämne. Detta kallas också för att göra en bred sökning. En bred sökning innebär att en stor del av sökresultatet inte kommer att vara relevant. Vid systematiska litteratursökningar är det vanligt med en precision omkring två-tre procent. I motsats till en bred sökning ger en smal (eller precis) sökning en högre andel relevanta träffar, men man riskerar då att missa viktiga studier. I bilden nedan kan du se hur de olika sökningarna förhåller sig till varandra.
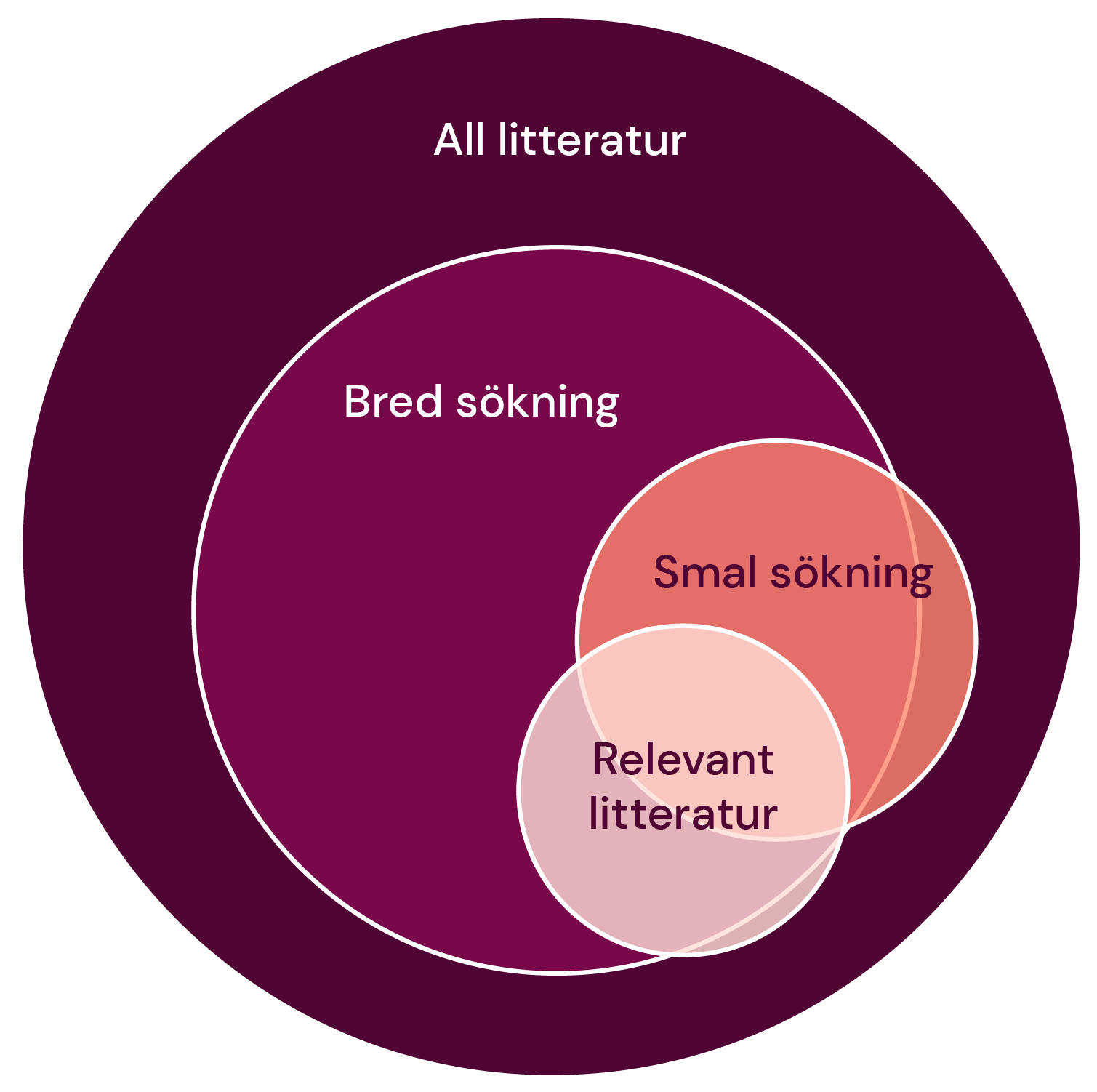
Bred sökning
+ Fångar upp mycket av den för frågeställaren relevanta litteraturen
- Kan ge en hel del irrelevanta träffar
Smal sökning
+ Har ofta hög träffsäkerhet
- Förlust av relevant litteratur
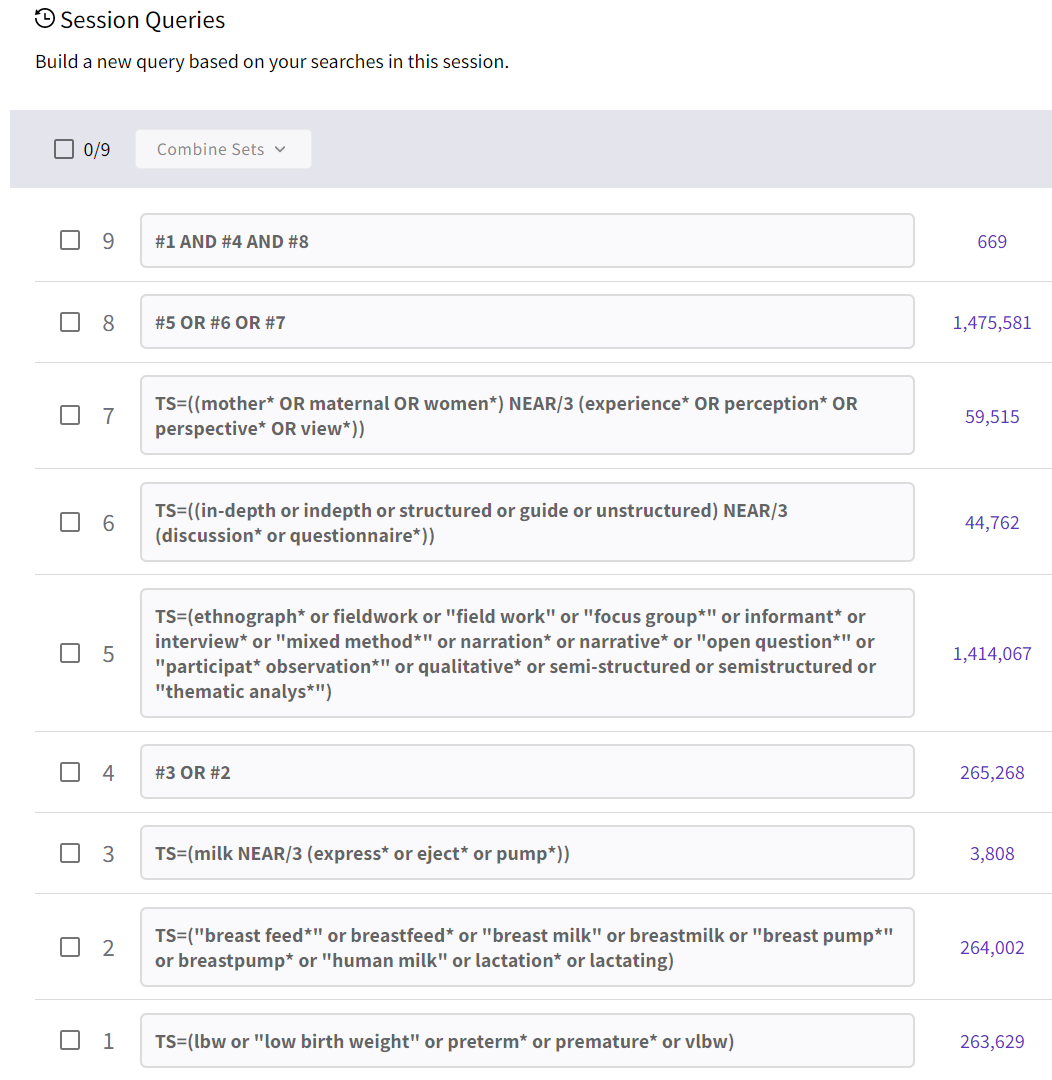
Sökstrategin byggs vanligen upp med flera olika sökblock, där varje sökblock innehåller både kontrollerade termer och fritextord. Sökstrategin översätts till flera olika databaser. Ibland inkluderas grå litteratur, exempelvis avhandlingar och kliniska prövningar. Databassökningen kan även kompletteras med andra sökstrategier, till exempel handsökning i utvalda tidskrifter, genomgång av referenslistor och citeringsanalys.
Det rekommenderas att sökstrategin granskas av ytterligare en person innan de slutgiltiga sökningarna görs. Som stöd för granskningen av sökstrategier finns en checklista: Peer Review of Electronic Search Strategies (PRESS).
Kom igång med litteratursökningen
Ofta är det bra att börja med att göra lite mer ostrukturerade sökningar i databaserna, så kallade testsökningar. När du testsöker kan du samtidigt börja undersöka terminologin inom området, och börja leta fler sökord.
Det är bra att se efter om det finns några redan publicerade litteraturöversikter inom ämnet. Ibland finns sökstrategierna bifogade som appendix.
Du bör också identifiera några nyckelartiklar, det vill säga centrala studier om ditt ämne. Det ska vara artiklar som så nära som möjligt motsvarar din forskningsfråga. Dessa nyckelartiklar kan du använda både för att bygga upp din sökstrategi och för att i ett senare skede testa samma sökstrategi: om inte nyckelartiklarna fångas upp av sökningen bör sökstrategin modifieras.
Du kan också se efter om det finns några validerade sökfilter som du kan använda. Sökfilter är en samling sökord som är utvalda för att fånga upp ett visst urval av referenser, till exempel artiklar med en viss studietyp.
Webbsidor med validerade sökfilter
Cochranes sökfilter för RCT-studier hittar du i Technical Supplement to Chapter 4: Searching for and selecting studies 3.6 Search filters (sidan 58-63)
InterTASC Information Specialists' Sub-group Search Filters Resource är kollaborativ resurs där du kan hitta många olika sökfilter, både publicerade och opublicerade.
En del sökfilter finns också integrerade i databaser som PubMed/MEDLINE, PsycInfo och CINAHL. I PubMed finns Clinical Queries där du med hjälp av sökfilter kan begränsa dig till exempelvis kliniska studier eller studier om Covid 19.
Hitta sökord
Arbetet med att hitta alla relevanta söktermer är en viktig del av den systematiska sökningen. Ofta är det bra att börja med en testsökning där du använder de ämnesord och synonymer som du redan känner till. Genom att ögna igenom titlar, abstract och ämnesord kan du hitta fler användbara sökord.
För att din sökning ska fånga upp så många som möjligt av de relevanta studierna bör du ha med både ämnesord och fritexttermer i din sökning.
Ämnesord används i databaser för att tagga alla artiklar om ett visst ämne. När du har med ämnesord i sökningen hittar du artiklar om ett ämne även om författarna har använt andra, närliggande ord.
Ofta tar det ett tag innan artiklarna i databasen har blivit taggade med ämnesord, så för att fånga nya artiklar behöver du även ha med fritextord i din sökning. En del databaser, till exempel Web of Science, har ingen ämnesordslista, där söker du enbart med fritextord.
Andra sätt att söka
För vissa typer av ämnen och forskningsfrågor kan det vara lämpligt att komplettera databassökningen med andra sökstrategier. Det kan till exempel handla om att handsöka i vissa utvalda tidskrifter, eller att göra en citeringssökning.
Vill du inkludera grå litteratur i översikten finns det särskilda databaser där du kan söka efter det. Ofta behöver du använda en modifierad och förenklad sökstrategi för att söka efter grått material. För att hitta rapporter från myndigheter och liknande kan du även behöva gå in på vissa utvalda organisationers och myndigheters webbsidor och söka direkt bland deras publikationer.
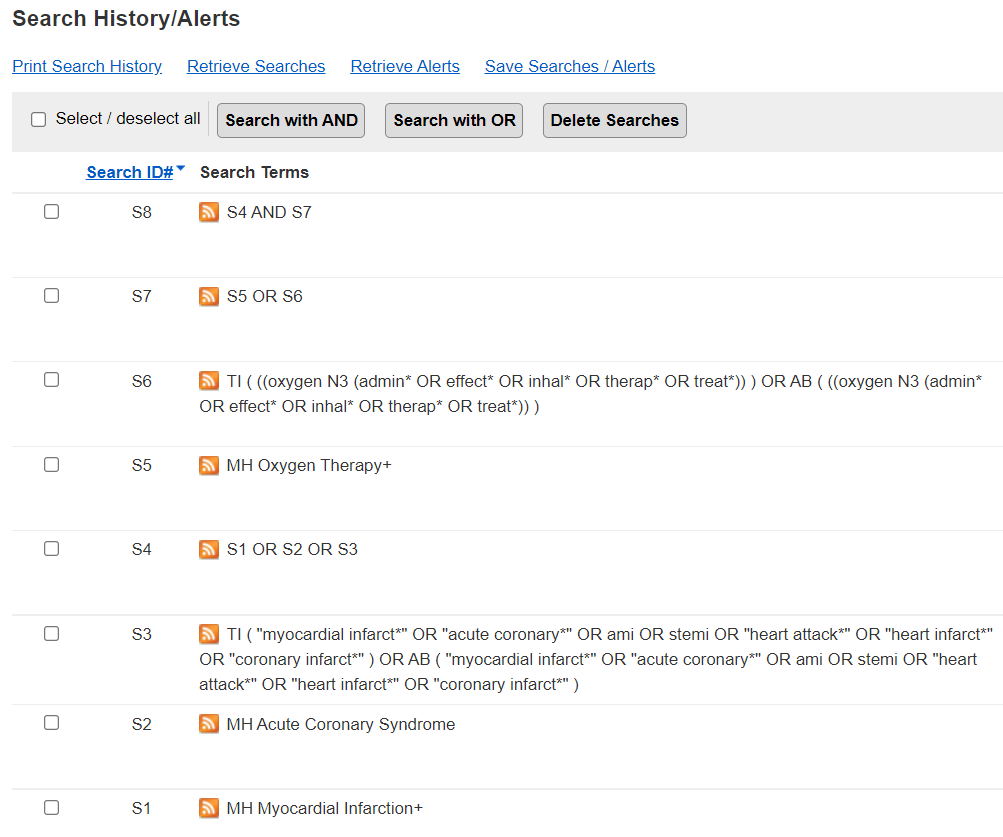
I samband med systematiska översikter är det även rekommenderat att göra en så kallad framåt- och bakåtsökning på de studier som inkluderas i översikten, dvs. att du går igenom citeringar och referenser till de inkluderade publikationerna. Det finns flera olika verktyg och databaser där du kan söka efter citeringsdata, några exempel är Web of Science, Google Scholar och SpiderCite.
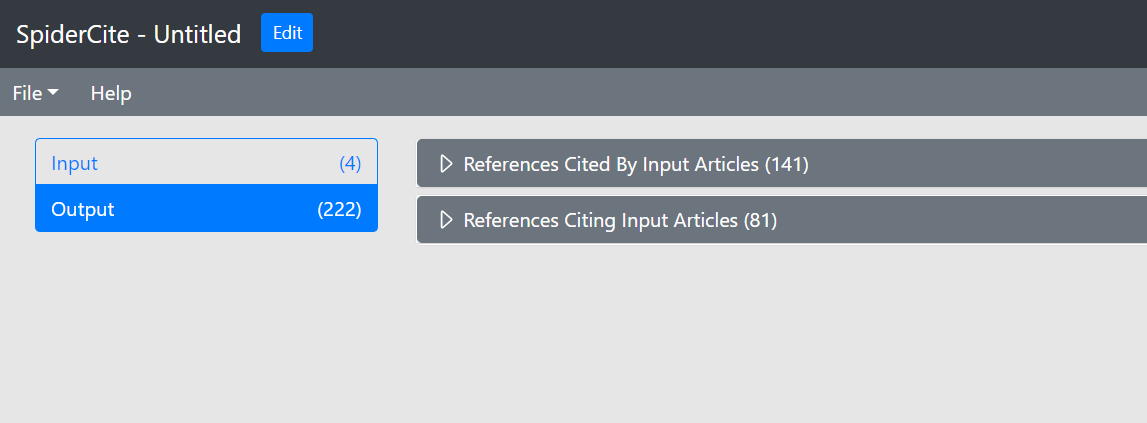

Sökexempel från olika databaser
För en systematisk översikt rekommenderas att du söker i flera olika databaser. Inom medicin och hälsa används ofta PubMed/MEDLINE, Embase och Cochrane Library. Beroende på ämnesområde kompletteras sökningen med en tvärvetenskaplig databas som Web of Science och/eller ämnesspecifika databaser som CINAHL, PsycInfo och ERIC.
Använd alltid samma sökblock och samma fritexttermer i alla databaser du söker i. Ämnesorden behöver du däremot anpassa till respektive databas kontrollerade vokabulär. Du behöver också anpassa fälttaggar och andra tecken.
I många databaser är grundinställningen att sökningen görs i alla fält (eller en kombination av flera olika fält). Vid systematiska litteratursökningar rekommenderas dock att du själv specificerar sökfält. Det ger dig mer kontroll över sökningen och gör även sökstrategin mer transparent.
Förutom tipsen under respektive databas nedan har sökargruppen på KIB utvecklat en databasmatris som ett internt stöd vid systematiska sökningar. Det finns också verktyg som kan hjälpa till med översättning av söksyntax mellan olika databaser, till exempel Systematic Review Accelerator Polyglot, som även finns i TERA The Evidence Review Accelerator.
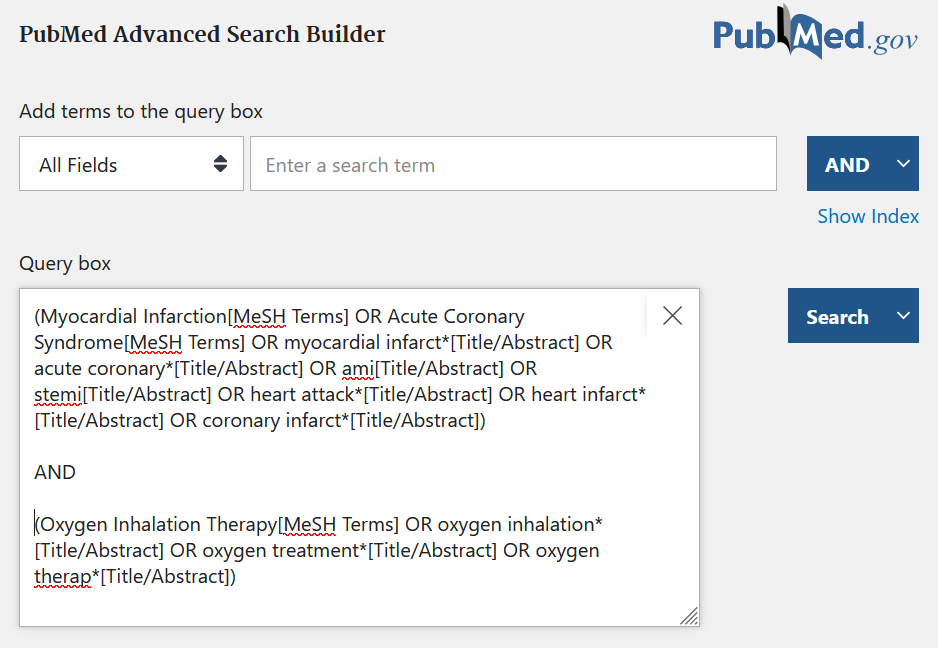
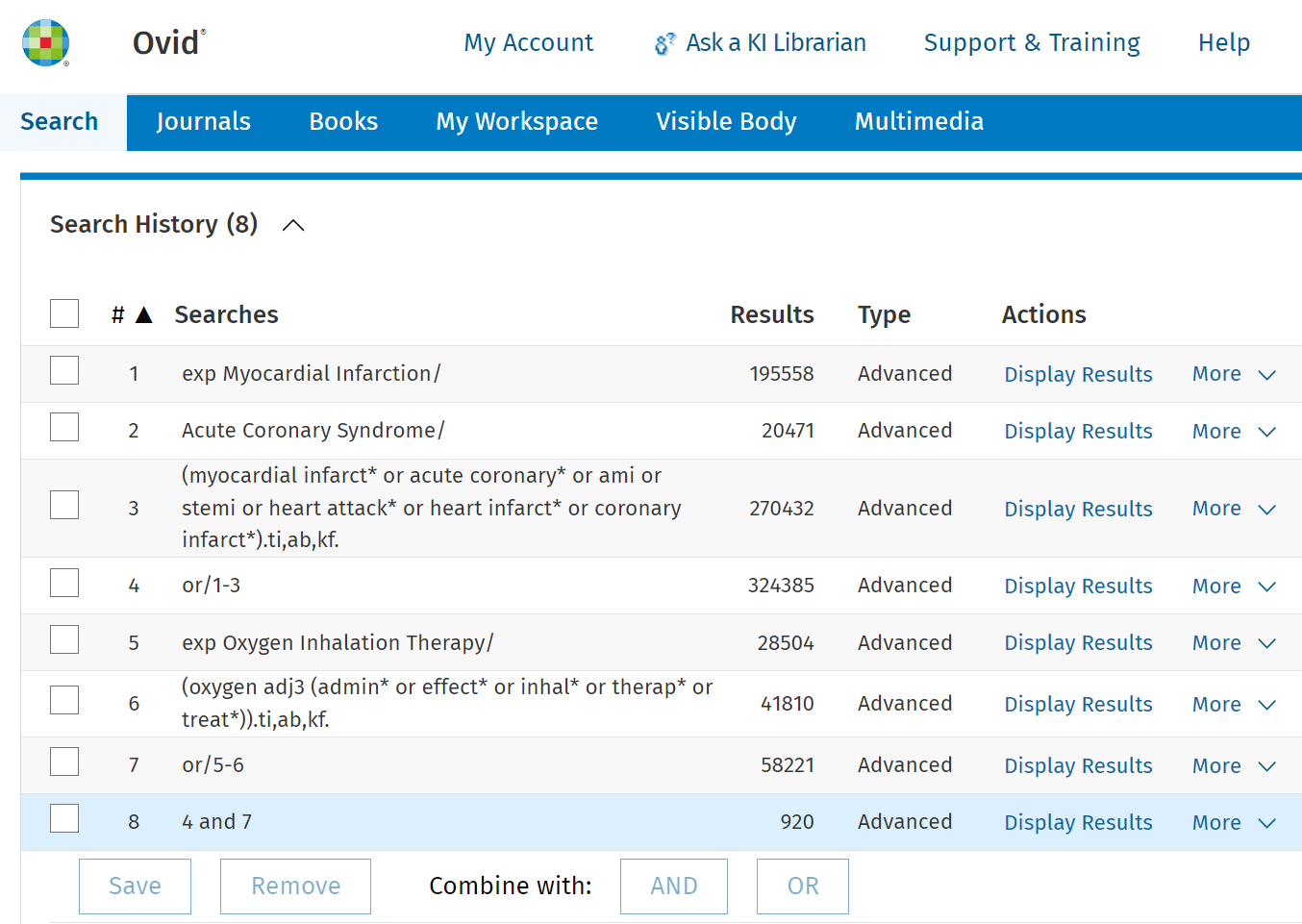
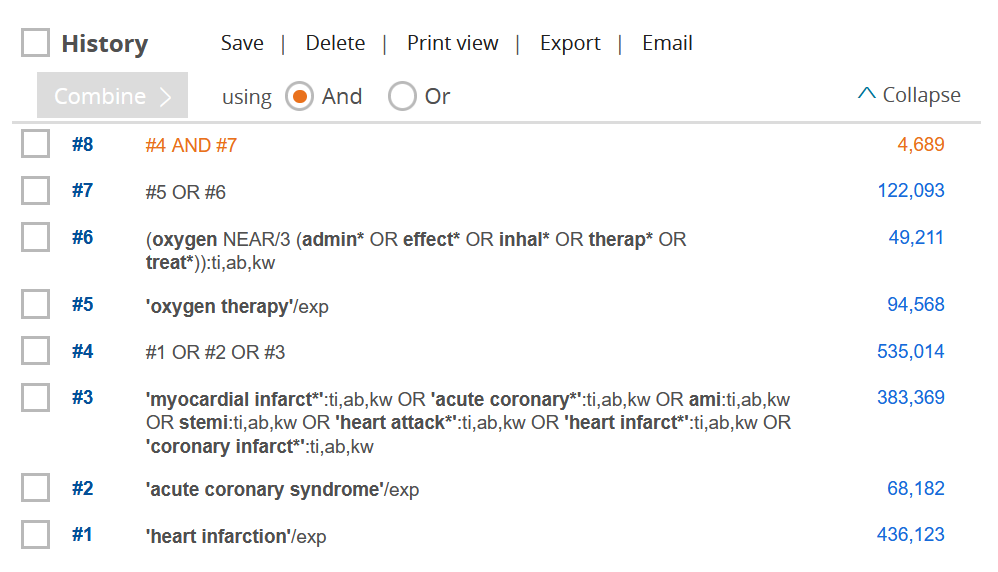
Dokumentation
PRISMA
Liksom vid all typ av forskning ska processen i en systematisk översikt vara transparent dokumenterad i alla delar, tydligt avrapporterad i den färdiga publikationen och reproducerbar.
Som ett stöd för hur systematiska översikter ska rapporteras finns en vedertagen standard: PRISMA Guidelines (Preferred Reporting Items for Systematic Reviews and Meta-Analyses). PRISMA 2020 består av en checklista med 27 punkter och flera olika flödesdiagram.
Enligt PRISMAs checklista ska alla databaser, register och andra källor som använts för att hitta studier, liksom det datum då varje källa senaste söktes, anges. Sökstrategin ska dokumenteras i sin helhet för respektive databas, och kan publiceras i ett appendix till den publicerade artikeln.
Det finns en särskild checklista för hur sökningen ska rapporteras, PRISMA-Search.
Uppdatera sökning innan publicering
Enligt Cochrane Handbook ska sökningen uppdateras inför publicering, om det har gått mer än tolv månader (helst sex månader) sedan den ursprungliga sökningen gjordes. Tidskrifter kan också kräva att sökningen uppdateras om det gått flera månader sedan artikeln skickades in.
Ett snabbt sätt att hitta nya artiklar är att göra om sökningen och begränsa till ett visst intervall av publiceringsdatum. Dock riskerar man då att missa material som lagts till retroaktivt i databasen. Ett säkrare sätt är att begränsa till det datum då artiklar lades till i databasen, eller att använda EndNote för att deduplicera de nya referenserna gentemot de gamla.
Läs mer:
- Bramer, W., & Bain, P. (2017). Updating search strategies for systematic reviews using EndNote. Journal of the Medical Library Association : JMLA, 105(3), 285–289
- Updating a search. University of South Australia.
Referenshantering
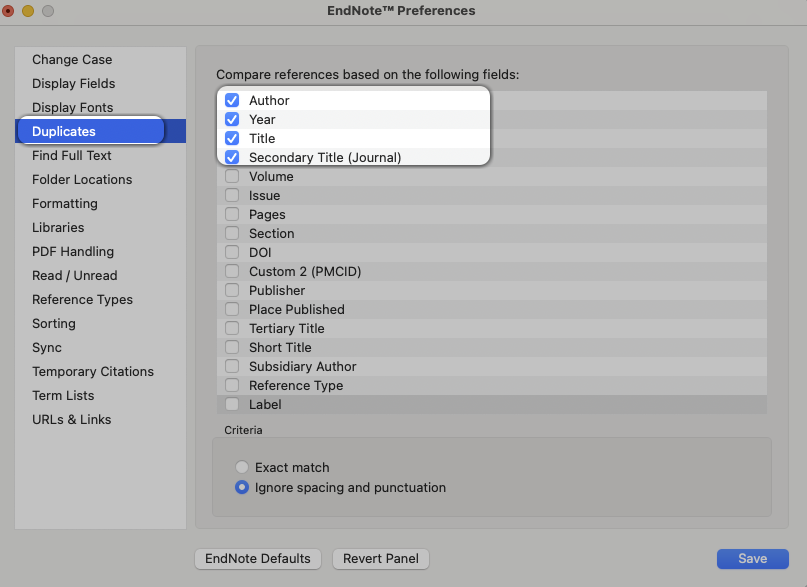
Systematiska litteratursökningar genererar ofta ett stort antal referenser. Eftersom man söker i ett flertal databaser tillkommer dessutom en större mängd dubbletter.
För att kunna hantera ett stort antal referenser rekommenderar vi att du använder ett referenshanteringsprogram, till exempel EndNote. Där kan du dels organisera dina referenser i grupper utifrån olika kriterier, dels få bort dubbletter.
Screening
När du ska gå igenom och välja ut de artiklar som matchar din forskningsfråga och dina inklusionskriterer kan det vara bra att ta hjälp av ett verktyg som är till för just detta. Som ansluten till KI har du tillgång till Covidence. Covidence är ett webbaserat verktyg som förutom screening även erbjuder stöd för kvalitetsbedömning, dataextrahering, PRISMA flödesschema mm.
På Covidence egna hjälpsidor hittar du korta filmer, artiklar och även inspelade webbinar där du kan lära dig hur kommer igång och använder programmet.
Det finns även andra screeningverktyg och nya tillkommer med jämna mellanrum.
Kontakta oss
Är du forskare på KI och vill ha hjälp med sökningen till din systematiska översikt? Kontakta gärna sökargruppen.

Om du vill att vi ska kontakta dig angående din feedback, var god ange dina kontaktuppgifter i formuläret nedan