Visualisering
Vid forsknings- och utvecklingsarbete behöver man kunna skapa och kritiskt granska visualiseringar av data och information. Inom biologi och medicin kan visualisering handla om allt från utforskande diagnostik till förklarande populärvetenskap. Här får du en introduktion till grunderna i visualisering av data, med ett särskilt fokus på visualiseringars kommunikativa funktion. För dig som vill fördjupa dig ytterligare har vi även en självstudiekurs i Canvas.

Självstudiekurs om visualisering
Vill du lära dig mer om visualisering? Universitetsbibliotekets öppna webbkurs ger dig en grundläggande introduktion till visualisering av forskningsdata. Genom fallstudier och praktiska övningar lär du dig att grafiskt representera och kommunicera data på ett effektivt och tillgängligt sätt. Kursen är engelskspråkig och riktar sig främst till doktorander och forskare.
Kommande event om visualisering
- 2026-02-17 - 12:15
- 2026-03-02 - 12:15
- 2026-03-18 - 13:00
För att öka förståelsen för hur visuellt material kan användas för att utforska och kommunicera data eller information går vi här igenom ett antal övergripande principer och riktlinjer som kan vara ett stöd i visualiseringsarbetet:
- Nyttan med visualisering
- Hur ditt syfte, din målgrupp och din vetenskapliga domän kan påverka utformningen av visualiseringar
- Hur kunskap om grafiska principer och mänsklig perception kan göra det lättare för dig att nå fram med ditt budskap
- Hur du kan koda och representera data på grafisk väg
Varför visualisera?
Att visualisera innebär att grafiskt synliggöra förhållanden eller tillstånd i ett avgränsat underlag, till exempel ett dataset. Syftet kan vara att:
- analysera och utforska data i jakt på ytterligare information eller kunskap
- förklara och förmedla den information och kunskap som data givit upphov till
Som vanligt när det gäller vetenskapligt arbete är det kvaliteten på och hanteringen av insamlad data som ligger till grund för vilken kunskap som kan genereras eller förmedlas med hjälp av en visualisering.
Anscombes kvartett
Ett klassiskt exempel som ofta används för att beskriva hur viktigt det är att visualisera data är det som populärt kallas Anscombes kvartett (läs mer i Graphs in Statistical Analysis av Francis Anscombe). Exemplet består av fyra dataset med x- och y-variabler. Alla dataset är mycket lika, med nästintill identiska statistiska mått för medelvärde, varians, korrelationskoefficient och linjär regression (streckad röd linje i figur).
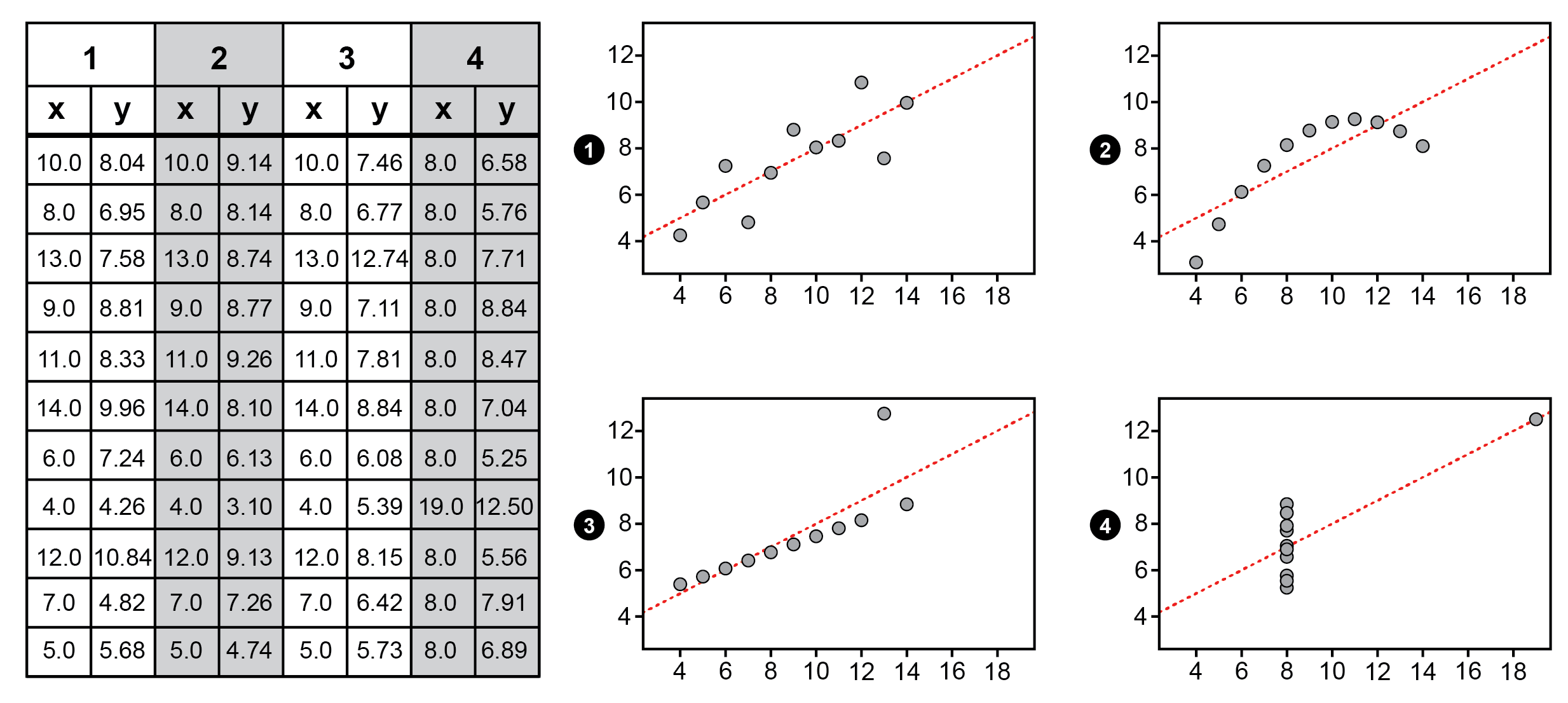
Genom att studera tabelldata och de statistiska måtten för dataseten kan en del slutsatser dras. Utan de visuella representationerna är det lätt att anta att sambandet mellan x och y är, mer eller mindre, detsamma i alla fyra dataset. När dataseten visas i grafisk form blir det dock tydligt att visualiseringarna lyckas avslöja mönster och beskriva data på ett sätt som tabellerna och de statistiska måtten inte själva kan, och graferna demonstrerar tydligt att dataseten i själva verket är mycket olika varandra med avseende på relationen mellan x- och y-variablerna.
Anscombes kvartett är ett överdrivet exemplet, men poängen är tydlig: visualisering borde vara en självklar del av analys och kommunikation av data.
Visualisering är ett kraftfullt kommunikationsverktyg för att det drar nytta av människors inbyggda förmåga att urskilja mönster, trender och avvikelser i allt vi ser. Det fungerar som ett kognitivt hjälpmedel som avlastar arbetsminnet och låter oss processa en stor mängd data snabbt och effektivt. Om detta går att läsa mer i artikeln A Tour through the Visualization Zoo från 2010, samt i ett av fältets centrala verk, boken Visualization Analysis and Design (2015) av Tamara Munzner.
Visualiseringars syfte och målgrupp
Syftet med en visualisering är kopplat till målgrupp och mottagare. Ett förenklat sätt att se på kopplingen mellan syfte och målgrupp är att beskriva en visualisering på en skala från utforskande till förklarande. Begreppen exploratory respektive explanatory, eller discover respektive present, används på engelska.

Utforskande och undersökande visualiseringar placeras i ena änden av skalan. Det kan till exempel handla om olika typer av explorativ dataanalys för att hitta samband i numeriska dataset, men också utforskande av icke-numeriska data, såsom bilddiagnostik i klinisk verksamhet eller olika varianter av mikroskopi. Målgrupp eller mottagare för sådana visualiseringar är personer med stor kännedom om dataunderlaget eller den aktuella kunskapsdomänen, som därmed har tillräckliga kunskaper för att utforska, analysera och omsätta visuella data till information och kunskap.
Syftet med en utforskande visualisering kan alltså, till exempel, vara att analysera forskningsdata, fatta beslut om nästa steg i en forskningsprocess eller riktning för en viss medicinsk behandling. Målgrupper är då den visualiserande forskaren själv respektive den medicinskt ansvariga klinikern.
I den andra änden av skalan finns förklarande visualiseringar, där målgruppen är mottagare som saknar djupare kunskaper om det aktuella ämnet. Exempel på förklarande visualiseringar hittar vi i populärvetenskaplig kommunikation, utbildningsmaterial och annan utåtriktad eller uppsökande verksamhet.
För att så effektivt som möjligt kommunicera potentiellt komplicerad information och kunskap är det helt avgörande att den presenteras på ett för syftet lämpligt sätt. Syftet med en förklarande visualisering kan till exempel vara att kommunicera resultatet av en studie, förklara och motivera val av behandling eller som en del i undervisningen. Målgrupper är då till exempel den intresserade allmänheten, patienten som behandlas eller universitetsstudenter.
Mellan de båda extremerna utforskande och förklarande ryms då enligt denna modell i princip allt visuellt kommunicerat vetenskapligt material, oavsett om visualiseringen är avsedd för användning i en konferenspresentation, en ansökan om forskningsanslag, en vetenskaplig artikel, etc. Skalan kan användas som ett sätt att klassificera och beskriva visualisering på, och bör inte ses som ett verktyg för bedömning eller värdering. Skalans ändar bör inte heller ses som varandras motpoler eftersom de snarare beskriver ett förhållande mellan subjektet (mottagaren) och objektet (dataunderlaget).
Grafiska principer
För datavisualisering som metod finns inga generellt fastslagna regler att applicera. Praxis och riktlinjer tenderar att utvecklas vid behov för att sedan accepteras som ett slags standard inom enskilda discipliner.

Bild från Wikimedia Commons (CC BY 3.0).
Ett exempel på detta är hur Jane S. Richardson, professor i biokemi, valde att grafiskt representera den sekundära proteinstrukturen betaflak som pilar i en artikel i Nature redan 1977. Richardsons visuella språk har sedan dess präglat visualiseringen av proteiner och blivit ett slags standard som fyller ett disciplinspecifikt behov.
Men vilka grafiska principer kan man behöva förhålla sig till på en mer allmängiltig nivå? För att hitta ett mer generellt och disciplinöverskridande teoretiskt fundament att bygga vidare på får vi vända oss till vår varseblivning (perception). Människans förmåga att se mönster och avvikande detaljer i en grafisk framställning är bärande inom visuell kommunikation. Det är den mänskliga perceptionen som ser till att vi, till exempel, kan skönja klusterbildning i ett sambandsdiagram, se trender i ett stapeldiagram eller separera färgade fält från varandra i en karta. Vår varseblivning möjliggör dessutom visuell tolkning av såväl helheten som delarna av en form eller figur, något som är i fokus inom den gren av psykologi som kallas gestaltpsykologi, där det formulerats en uppsättning principer som kan utnyttjas för att skapa tydligare visualiseringar. En grundligare genomgång av varseblivning, och de gestaltprinciper som ofta associeras till datavisualisering, finns tillgänglig på sidan om grafiska principer. Hur de teoretiskt fungerar beskrivs först kortfattat, varpå exempel på hur de praktiskt tillämpas presenteras.
Grafisk kodning – att presentera information visuellt
Även om man är väl förtrogen med ett dataset kan det vara svårt att veta vad som är det bästa och mest effektiva sättet att beskriva det visuellt på. För att kunna svara på den frågan räcker det inte att förstå den teoretiska grunden för visualisering. Det behövs även verktyg som hjälper oss att omsätta teori till praktik.
I den här fasen av visualiseringsarbetet är begreppet kodning centralt. Det är en fri översättning av det engelska begreppet encoding, den term som ofta används i visualiseringssammanhang. Grafisk kodning handlar om hur data och information kan "översättas" till grafiska representationer. För att använda ett väldigt grundläggande exempel kan det röra sig om att utgå från siffran femtio procent, och visualisera denna som en halva i ett cirkeldiagram.
Det finns många olika sätt att beskriva den grafiska kodningen på. En av de mest grundläggande och inflytelserika texterna är William S. Cleveland och Robert McGills Graphical Perception: Theory, Experimentation, and Application to the Development of Graphical Methods, från 1984. Jock Mackinlay byggde sedan vidare på deras forskning i sin artikel Automating the design of graphical presentations of relational information, publicerad 1986.
Anledningen till att dessa artiklar blivit så tongivande är i mångt och mycket deras empiriskt verifierade, rangordnade och praktiskt användbara listor över vilka grafiska representationer av data som människans perception har olika lätt eller svårt för att tolka på ett korrekt och effektivt sätt. När vi visualiserar data görs detta med hjälp av att symboler med olika former och färger positioneras på olika sätt, för att till exempel illustrera 50% i ett cirkeldiagram. Betraktaren av visualiseringen måste sen avkoda denna grafiska representation på lämpligt sätt. Cleveland och McGills lista visar, med fokus på kvantitativa data, vilka slags visuella signaler (visual cues på engelska) är lättast att avkoda:
- Position on a common scale
- Position on a non-aligned scale
- Length
- Direction
- Angle
- Area
- Volume
- Curvature
- Shading
- Color saturation
Medan Cleveland & McGills lista fokuserar enbart på hur vi människor tolkar representationer av kvantitativa data rangordnar Mackinlay varseblivningsrelaterade processer med hänsyn till tre olika typer av underliggande data: förutom kvantitativa data beskriver hans listor även olika metoder för att på grafisk väg representera ordinaldata och nominaldata.
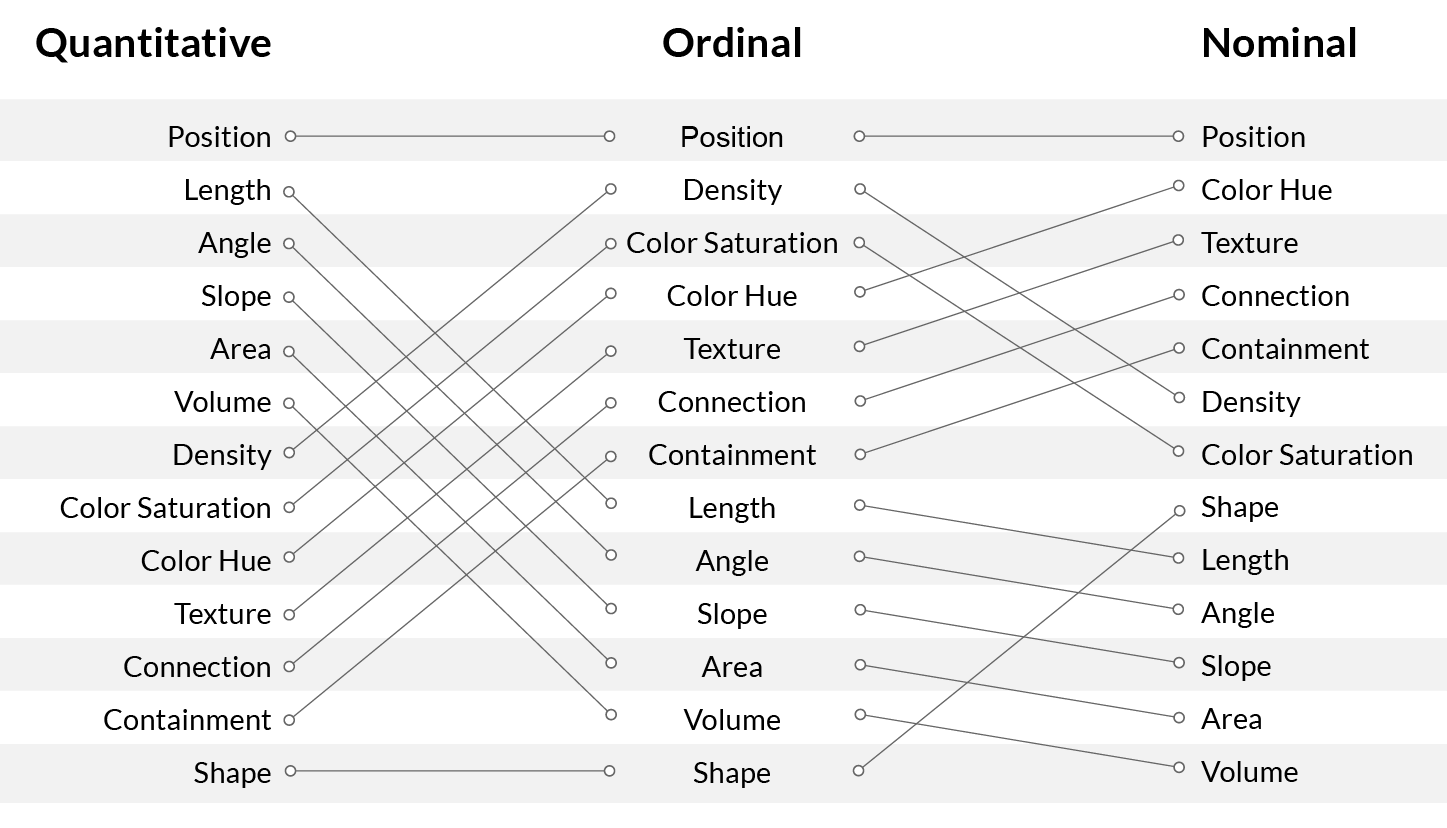
Tabellen ovan visar hur till exempel en stapels höjd, det vill säga position, i ett diagram kan vara ett effektivt sätt att representera kvantitet på. Detsamma gäller angle (vinkel), till exempel på en linje mellan olika mätpunkter i ett linjediagram: ju brantare lutning, desto större förändring i värde.
Color hue (kulör), å andra sidan, fungerar sämre för att ange mängd, men däremot bättre för att uttrycka nominaldata, till exempel olika kategorier.
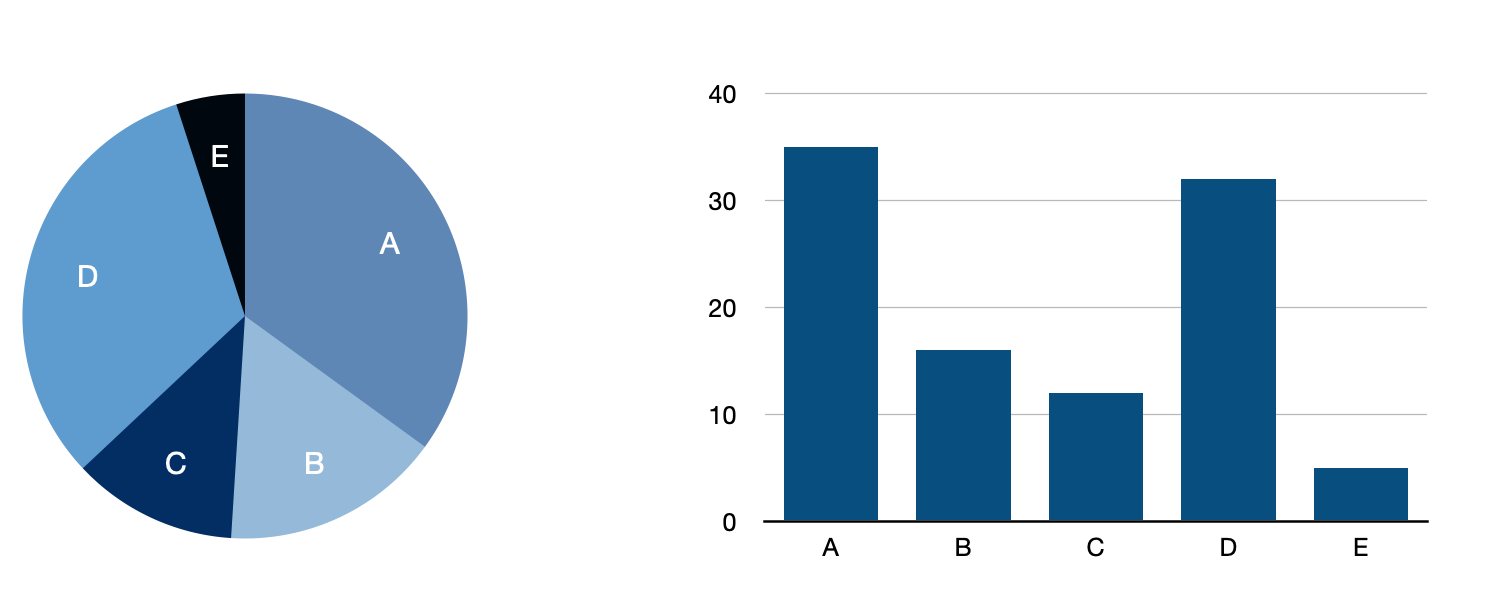
Detta blir tydligt i ett enkelt cirkeldiagram där vinkeln på "tårtbiten" beskriver hur stor del av helheten som åsyftas (det kvantitativa) och färgen lämpligen används för att särskilja aktuell tårtbit från övriga (det nominala).
Staplarna i diagrammet intill är baserade på samma data. Den lilla skillnaden i kvantitet mellan A och D blir tydligare här, trots att tårtbitarnas area i cirkeldiagrammet visar exakt samma sak. Position i höjdled har lättare att förmedla absoluta och jämförbara värden. Att olika typer av diagram fungerar olika bra i olika situationer hänger ihop med det som brukar benämnas effektivitet och expressivitet, något du kan läsa mer om nedan. Det är även klokt att förhålla sig till Cleveland & McGills samt Mackinlays rankingar och tabeller som rekommendationer snarare än en absolut sanning.
Om du vill fördjupa dig
- Ett kompletterande perspektiv till Cleveland, McGill och Mackinlay hittar du hos Tamara Munzner i hennes bok Visualization Analysis and Design (2015). Munzner utgår också från ett liknande system med ranking av visuella och kognitiva processer, men de benämns annorlunda och indelningen följer en annan logik; olika datatyper (kategoridata, ordinaldata/kvantitativa data, relationell data) kodas med fördel av vissa marks (geometriska former och figurer såsom punkter, linjer, areor etc.), vars utseende bestäms av visual channels (position, färg, vinkel, storlek etc.). Genom att, steg för steg, besvara en fråga i taget kan Munzners system hjälpa dig att landa i en lämplig form för din visualisering och undvika de värsta fallgroparna och misstagen.
- I ett informativt och pedagogiskt blogginlägg av Nathan Yau (2010) finns en kommenterande analys av den lista som Cleveland & McGill presenterar, och där hittar du även grafiska exempel.
- Att koda information med hjälp av färg är något av ett specialfall. De begrepp som i Mackinlays tabell benämns color hue (nyans) och color saturation (mättnad), och i viss mån även begreppet texture (mönster, i det här sammanhanget), är mer komplicerade och förknippade med fler undantag än många av de andra begreppen. På vår sida om färg kan du lära dig mer om detta.
Bra visualiseringar är expressiva och effektiva
I artikeln Automating the design of graphical presentations of relational information (1986) beskriver Jock Mackinlay grafiska representationer som ett visuellt språk. En visualisering, en graf eller ett diagram till exempel, utgör således en mening (sentence) uttalad på detta språk. Mackinlay föreslår två designkriterier för att både formulera och utvärdera meningar på detta språk; expressivitet och effektivitet.
Expressivitet
En visualiserings expressivitet är ett mått på hur väl den förmår förmedla allt som dataunderlaget innehåller och enbart det som dataunderlaget innehåller. Med andra ord behöver data visualiseras på ett tydligt och transparent sätt såsom det är, varken mer eller mindre. Jeffrey Heer, University of Washington, förklarar den här principen på ett något mer lättförståeligt sätt: "Tell the truth and nothing but the truth (don’t lie, and don’t lie by omission)."
Effektivitet
En visualiserings effektivitet är ett mått på dess begriplighet, hur väl den kommunicerar det som uttrycks och hur väl den tas emot av betraktaren. Kriteriet är förknippat med Mackinlays rangordnade lista. Även denna princip förklarar Jeffrey Heer på ett enklare sätt: "Use encodings that people decode better (where better = faster and/or more accurate)."
Det visuella språket
För att kunna formulera vad som på Mackinlays "visuella språk" utgör en fullständig mening behöver vi alltså ta hänsyn till designkriterierna expressivitet (vad som förmedlas) och effektivitet (hur det förmedlas), och samtidigt ta hänsyn till dataunderlagets karaktär. Det är en bra början. Det kan ibland dock vara svårt välja rätt diagram (eller om vi fortsätter att följa språkanalogin: det kan vara svårt att formulera meningen rätt). Tänk på att processen är iterativ och att man kan behöva formulera om sin mening flera gånger innan den blir tillräckligt expressiv och effektiv.
Som vi konstaterade i vår jämförelse mellan cirkeldiagram och stapeldiagram har olika diagramtyper olika styrkor och förmågor. Just användningen av cirkeldiagram är något som ofta kritiseras; de är inte tillräckligt exakta, det är svårt att jämföra storleken på tårtbitarna, och så vidare. Kritiken är inte obefogad, men cirkeldiagram har också vissa fördelar. Det går, till exempel, oerhört snabbt för oss att avkoda ett cirkeldiagram, framförallt ett med få och tydliga tårtbitar. Det är dessutom en diagramtyp som många känner igen. Om du väljer att visualisera data med en ovanlig diagramtyp kan det bli svårare för din målgrupp att tolka visualiseringen, just av den enkla anledningen att de inte är vana vid den diagramtypen.
Tänk även på att en visualisering inte alltid består av grafer och diagram av data. Istället kan underlaget utgöras av bilddata eller omfattande bildserier. Den kan till exempel röra sig om grafiskt material genererat av ett mikroskop, en tomograf eller någon annan avancerad utrustning. Även här kan Mackinlays tabell eller Munzners begrepp vara ett stöd i valet av vilka visuella kanaler som kan eller bör kodas, och i så fall hur.
Att välja rätt visualisering i praktiken
Vad ska man då tänka på när man rent praktiskt vill visualisera ett dataset? Det mest centrala är kanske att välja vilken typ av diagram/graf man vill använda sig av. Ett dataset kan ofta visualiseras på flera olika sätt, vilket exemplet ovan med cirkel- och stapel-diagrammen visar. Det är inte alltid lätt att veta vilket slags diagram som är mest lämpligt, men det finns ett antal frågor man kan ställa sig för att visualisera data på ett så bra sätt som möjligt:
- Vad är det för slags dataset? För vissa dataset är det enkelt att välja diagram. Vill man visa korrelationen mellan två variabler är ett spridningsdiagram (scatter plot på engelska) ett självklart val. Men om man vill jämföra medelvärden för två variabler finns det fler val, till exempel stapeldiagram eller boxplot. I sådana fall är det extra viktigt att ställa sig frågan i nästa punkt:
- Vad är poängen med visualiseringen? Att visualisera ett dataset innebär ofta att man vill få fram ett specifikt budskap. Det kan till exempel vara att medelvärdet för olika grupper skiljer sig åt, att det sker en förändring över tid, eller att två variabler är korrelerade med varandra. Fundera på vad som egentligen är det centrala budskapet med din visualisering, och välj det diagram som passar bäst för att få fram budskapet.
- Vilka är mottagarna? En visualisering bör anpassas till den tilltänkta mottagaren. Riktar man sig till allmänheten måste kanske budskapet förenklas eller delas upp i flera delar, men om mottagaren är andra forskare kan ett diagram vara mer innehållsrik och detaljerat. Här kan också den specifika disciplinen spela roll. I vissa forskningsfält är vissa typer av diagram vanligare än i andra fält, och då kan det vara lämpligt att följa de konventionerna.
Utöver dessa punkter är det oftast bäst att försöka göra visualiseringen så enkel och tydlig som möjligt. Ta bort onödiga delar, se till att axlar och kategorier är tydligt utmärkta, och var konsekvent i användandet av typsnitt och färger. Och till sist, ha också expressiviteten i åtanke, alltså se till att visualiseringen återger data på ett tydligt och transparent sätt.
Det finns många resurser tillgängliga när du söker efter rätt diagram. Vi har samlat några av dessa på sidan om resurser för visualisering. Om du vill ha en snabb översikt över många olika sorters diagramtyper och deras användningsområden, eller vill inspireras av konkreta grafiska exempel på hur andra har visualiserat en viss typ av data, så kan vi rekommendera datavizproject.com.
Rekommenderad läsning
Även om visualisering av data är ett förhållandevis avgränsat fält finns det en uppsjö artiklar och lärresurser att tillgå. Så var ska du börja, om du är helt ny på området? Här är fyra tips:
- På universitetsbibliotekets webbsidor om visualisering hittar du ytterligare guider till grunderna i visualisering. Vi har även en öppen självstudiekurs i ämnet för dig som vill fördjupa dig. Målgrupperna för dessa öppna lärresurser är forskare och doktorander, men även du som är student kan ha användning av materialet.
- Tamara Munzner beskriver i sin bok Visualization Analysis and Design (2015) ett komplett system för visualiseringsarbete, med såväl teoretiska diskussioner som praktiska tillämpningar. Boken ger en matnyttig fördjupning och renodlar tidigare lärdomar och kunskaper till något sammanhållet och hanterbart, möjligt att omsätta i praktiken för både nybörjare och mer erfarna inom området. Boken finns tillgänglig som e-bok via biblioteket.
För en mer kompakt översikt i ämnet kan vi rekommendera två artiklar som publicerades 2021, som tillsammans sammanfattar dels de teoretiska grunderna för visualisering av data, dels den praktiska tillämpningen av dessa:
- Franconeri, Padilla, Shah, Zacks & Hullman. (2021). The Science of Visual Data Communication: What Works, Psychological Science in the Public Interest, 22(3), 110-161. DOI: 10.1177/15291006211051956. Artikeln finns tillgänglig via biblioteket. Detta är en översiktsartikel inriktad på de riktlinjer och principer som anses vara den teoretiska basen för kommunicerande visualisering. Författarna går igenom grafisk kodning av data med hänsyn till mänsklig perception. Artikeln fungerar som en effektiv sammanfattning av rådande forskning.
- Schwabish. (2021). The Practice of Visual Data Communication: What Works, Psychological Science in the Public Interest, 22(3), 97-109. DOI: 10.1177/15291006211057899. Artikeln finns tillgänglig via biblioteket. Denna artikeln fungerar som en praktiskt orienterad kommentar till den mer teoretiskt inriktade artikeln av Franconeri et al. Schwabish lyfter en handfull praktiska principer att arbeta efter och gör en särskild poäng av att sänka trösklarna för att börja skapa visualiseringar. Han betonar att visualiseringar inte är något som enbart kan utföras av experter eller något som kräver avancerad och/eller dyr mjukvara.

Om du vill att vi ska kontakta dig angående din feedback, var god ange dina kontaktuppgifter i formuläret nedan